Chapter 12 pertains to Computability Theory, which attempts to distinguish between problems that are computable and those that are not. Focusing on decision problems, this distinction is between languages that are decidable (recursive) vs. undecidable (not recursive). The class of undecidable languages can be further partitioned into those that are "semi-decidable" (recursively enumerable (RE), but not recursive) and those that are not even RE.
Complexity theory, on the other hand is concerned with the resource requirements of algorithms that decide languages. These resources are time and space (amount of memory). Linz focuses upon time complexity and says little about space complexity.
Definition 14.1: A Turing machine decides a language L in time T(n) if, for every w ∈ Σ*, M halts in ≤ T(|w|) moves with its verdict (ACCEPT or REJECT). If M is nondeterministic, w ∈ L(M) iff there exists some sequence of moves that leads to an ACCEPT verdict.
Definition 14.2:
A language L is a member of DTIME(T(n)) if there exists a
deterministic multi-tape Turing machine that decides L in time O(T(n)).
A language L is a member of NTIME(T(n)) if there exists a
nondeterministic multi-tape Turing machine that decides L in time O(T(n)).
Of course, DTIME(T(n)) ⊆ NTIME(T(n)), because deterministic TM's are special cases of nondeterministic TMs. Also, if T1(n) ∈ O(T2(n)) (which is to say that, as n grows, T1(n) grows no more quickly than does T2(n)), we also have DTIME(T1(n)) ⊆ DTIME(T2(n)).
In the realm of polynomial versions of T:
Theorem 14.3: for every integer k≥1, DTIME(nk) ⊂ DTIME(nk+1).
Notice the inclusion is proper. It follows that the hierarchy of time complexity classes is infinite, even among those T that are polynomials.
In Section 14.3, Linz makes connections between this hierarchy and the Chomsky hierarchy of languages. He notes that LREG ⊆ DTIME(n), which is to say that for every regular language there is a linear-time algorithm that decides it. (This is not surprising, as every regular language has a DFA that describes it, and we can simulate the computation of a DFA on a given string in time proportional to the length of that string, as following each transition in the DFA takes constant time.)
It also turns out that LCF ⊆ DTIME(n3), which is to say that for every context-free language there is a cubic-time algorithm that solves it. This follows from the CYK algorithm. Also, LCF ⊆ NTIME(n). This makes sense, as one would expect to be able to simulate the computation of a PDA in linear time.
However, Linz points out that the connection between the language classes in Chomsky's hierarchy and those in the DTIME() and NTIME() hierarchies is not particularly clear.
What seems more interesting and fruitful is to consider the classes
|
and |
|
P is the set of all languages that are accepted by polynomial-time (deterministic) algorithms. Meanwhile, NP is the set of all languages that are accepted by polynomial-time (nondeterministic) algorithms.
Of course, P ⊆ NP, but no one knows whether this inclusion is proper! That is, no one knows the answer to the question "Is P = NP?"
It turns out that most practical problems of interest that are (known to be) in P tend to be in, at worse, DTIME(n3). Thus, even though all but very small instances of a problem that is in DTIME(n100) —but not in DTIME(n99)— would take an unrealistic amount of time for a computer to solve, we informally apply the term tractable to all problems in P, to distinguish them from the intractable problems (i.e., those that are not members of P). (Such problems would be ones for which any algorithmic solution would have a running time that grows more quickly than any polynomial. Examples are problems that are in DTIME(2n) but not in P.)
In Section 14.5, Linz presents some examples of problems in the class NP that are not known to be in P. Indeed, these problems are among the "hardest" problems in NP; such problems are referred to as being NP-Complete. (A more detailed explanation is found below.)
The problem is this: Given a CNF expression, does there exist a truth-assignment to the variables that "satisfies" the expression (i.e., makes it evaluate to true)?
The obvious deterministic algorithm iterates through every possible assignment of truth-values to the variables in an attempt to find one that makes the expression evaluate to true. If one is found, the algorithm outputs YES; if none is found, it outputs NO. Because there are 2m distinct truth-value assignments to the m variables, this takes, in the worst case, exponential time. Better deterministic algorithms are known, but none that run in polynomial time.
Now consider a nondeterministic algorithm for this problem. It "guesses" a truth-assignment for the variables, evaluates the expression with respect to that truth-assignment, and outputs "YES" (respectively, "NO") if the result comes out to true (resp., false). Of course, if a satisfying truth-assignment exists, there is a "correct guess" that leads to a YES output. If there is no satisfying assignment, there is no correct guess and thus all possible executions of the algorithm produce NO. (Remember, a nondeterministic decision algorithm is defined to accept a string iff at least one possible computation on that string results in it printing YES, even if others result in the printing of NO.)
Making a guess about the truth assignment and checking to see whether the expression yields true with respect to that assignment take polynomial time. Hence, SAT ∈ NP.
No polynomial-time deterministic algorithm is known for this problem. A solution that takes time proportional to n! (or slightly worse) is to generate every possible permutation of the vertices (of which there are m! if there are m vertices) and, for each one, determine whether it corresponds to a path in the graph.
The nondeterministic version of the algorithm is this:
A polynomial-time nondeterminstic solution is this:
As far as anyone knows, there is no deterministic polynomial-time algorithm for this problem.
It turns out that the problems described above, and many others, are all related by the fact that, if any one of them is a member of P (i.e., is solvable by a polynomial-time deterministic algorithm), then all of them are in P and, moreover, P = NP! Problems of this kind are said to be NP-Complete.
The key concept used in showing a problem to be NP-Complete is that of polynomial-time reducibility.
Definition: A language L1 is said to be polynomial-time reducible to language L2 if there exists a polynomial-time deterministic algorithm by which any string w1 (over the alphabet of L1) is transformed into a string w2 (over the alphabet of L2) such that w1 ∈ L1 iff w2 ∈ L2.
As a trivial example of a polynomial-time reduction, consider the languages L1 = {w ∈ {0,1}* | w has more 0's than 1's } and L2 = {w ∈ {0,1}* | w has fewer 0's than 1's }.
A polynomial-time reduction of L1 to L2 is this: Given w1, produce w2 by flipping each bit (i.e., replacing each occurrence of 0 by 1 and each occurrence of 1 by 0).
Reduction from SAT to 3SAT: A more interesting polynomial-time reduction is sketched by Linz in Example 14.9, where he claims that any CNF expression E can be transformed into a 3-CNF expression E' (a CNF expression in which every clause has exactly three literals) such that E is satisfiable iff E' is satisfiable. The reduction goes like this:
Let E = C1 ∧ C2 ∧ ... ∧ Cm be a CNF expression, where each Ci is a clause, and hence of the form L1 ∨ ... ∨ Lk, where each Li is a literal (meaning either a variable x or negated variable ¬x).
The reduction replaces each clause C in E by one or more clauses, like this: Suppose that C = L1 ∨ ... ∨ Lk.
For example, the four-literal clause x1 ∨ x2 ∨ x3 ∨ x4 would be replaced by
Meanwhile, the five-literal clause x1 ∨ x2 ∨ x3 ∨ x4 ∨ x5 would be replaced by
Of course, the relevant points are that
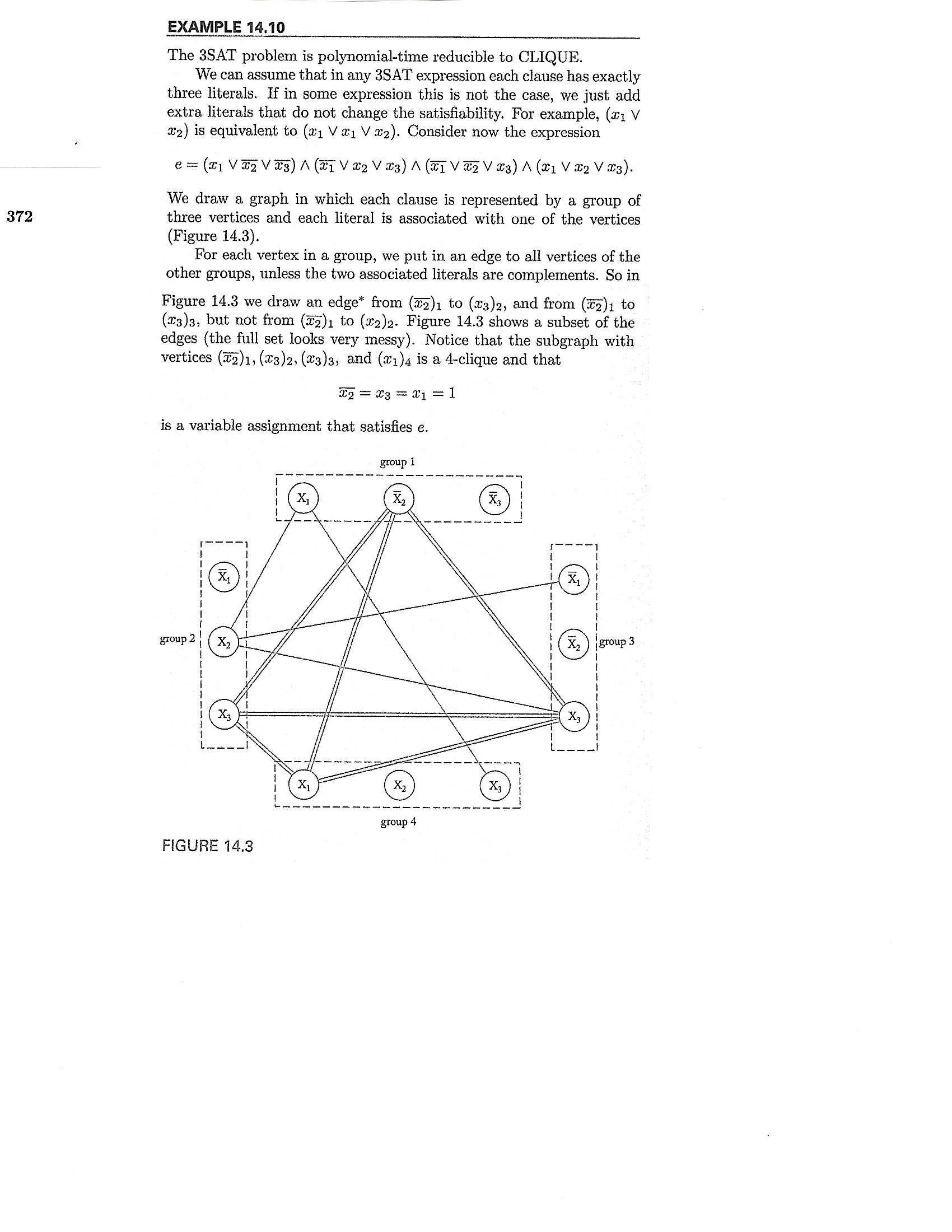
Reduction from 3SAT to CLIQUE: In Example 14.10, Linz presents a polynomial-time reduction from 3SAT (Given a 3-CNF expression, is it satisfiable?) to CLIQUE. See Figure 14.3 for an example.
|
|
Transitivity of polynomial-time reducibility: Note that polynomial-time reducibility is transitive. That is, if L1 is reducible to L2 and L2 is reducible to L3, then L1 is reducible to L3.
Thus, the two examples above demonstrate that SAT is polynomial-time reducible to CLIQUE. (One example shows that SAT reduces to 3-SAT; the other shows that 3-SAT reduces to CLIQUE. By transitivity of polynomial-time reduction, it follows that SAT reduces to CLIQUE.)
Definition: A language L is said to be NP-Complete if L ∈ NP and every language in NP is polynomially-time reducible to L.
Due to the transitiviy of polynomial-time reducibility, if L is NP-Complete and it is reducible to L2 ∈ NP, then L2 is also NP-Complete.
If we had some language/problem that was known to be NP-Complete, then it would open the door to showing, via polynomial-time reductions, that other languages/problems were also NP-Complete. But where do we get such a language?
Stephen Cook (and, independently, Levin) brilliantly proved that every problem in NP is polynomial-time reducible to SAT. Cook proved this by showing that for any nondeterministic TM M that runs in polynomial time, and for any input string w, a CNF E could be constructed, in polynomial time, such that M accepts w iff E is satisfiable.
The reason why the NP-Complete concept is meaningful is this:
Theorem: If L1 is polynomial-time reducible to L2 and L2 ∈ P, then L1 ∈ P. It follows that if any NP-Complete problem is solved by a determinstic polynomial time algorithm, the same could be said for every problem in NP, from which it would follow that P = NP.
For fifty years, researchers have been trying to either prove or disprove the equation P = NP, but no one has succeeded.